环境:v4.0.9
tidb:4个实例
tipd:3个实例
tikv:7个实例
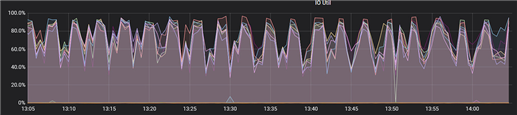
1. 在监控面板看到IO很高接近90多,如下图:
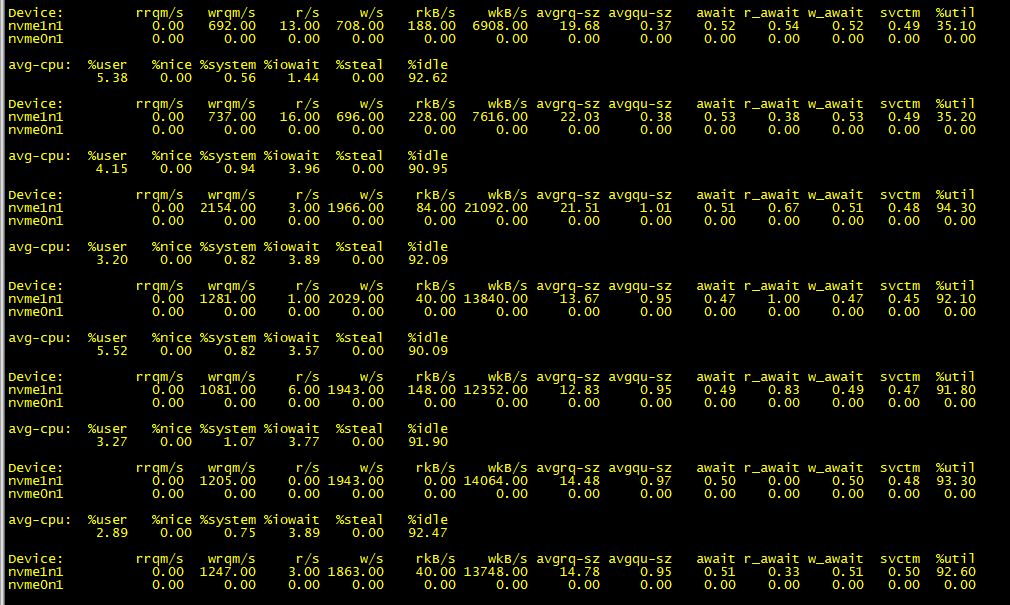
2. 针对其中一个tikv节点排查
通过iostat -x 1查看,可以看出都是磁盘写入
3. 查看io占用的线程比例

发现jbd2占用比例最大,还有tikv-server
4.jbd2引起磁盘 io 高,网上也有很多类似案例,总结起来有几方面原因:
- 系统 bug
- ext4文件系统的相关配置问题
- 其他进程的 fsync,sync 操作过于频繁
首先排除系统 bug因素,网络上反馈的问题在很低的版本,我们生产环境为 Centos 7.4,其次,查阅了 /proc/mounts 等信息,发现文件系统配置参数与其他环境差异不大,按照网上提供的关闭某些特性,降低 commit 频率等理论来说会有效果,但需要重新 mount 磁盘,相关组件都要重启,并且这看起来并非根本原因。
尝试分析 sync 调用,使用 sysdig 最方便,但现场环境安装很麻烦,因此开启几个内核 trace查看:
在 jbd2执行 flush 时输出日志
|
1
2
3
|
echo 1 > /sys/kernel/debug/tracing/events/jbd2/jbd2_commit_flushing/enable
|
在任意进程执行 sync 时输出日志
|
1
2
3
|
echo 1 > /sys/kernel/debug/tracing/events/ext4/ext4_sync_file_enter/enable
|
然后观察日志输出:
cat /sys/kernel/debug/tracing/trace_pipe
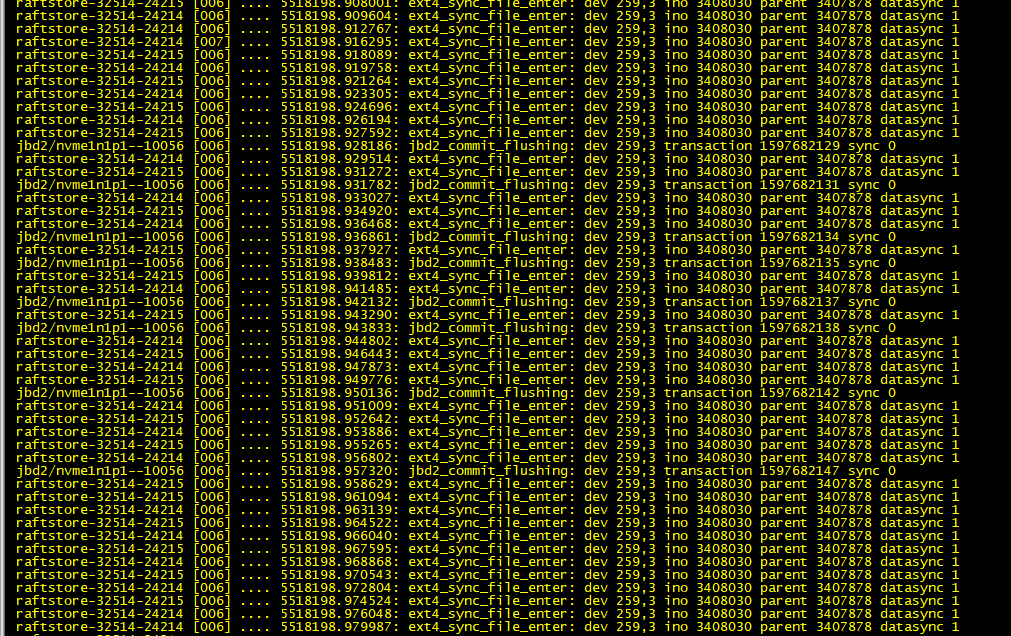
可以看到 jbd2和 raftstore-32514-24214进程有大量的 sync,瞬间刷出大量日志,因此基本确定raftstore-32514-24214进程。24214为 raft 进程的 tid,ps 看一下是哪个任务导致的:

5. 梳理一下TiKV配置中raftstore的参数,注意到raftstore.sync-log的嫌疑较大

由上述文字不难推测出,如果sync-log = false,那么写入Raft log时只会调用write()写入到缓冲区,而不会调用fsync()立即强制持久化。反之,如果sync-log = true,就会调用fsync()了。
结合JBD2的作用,基本可以确定是sync-log开关打开导致频繁fsync(),进而造成其I/O占用居高不下。于是我们修改TiKV的配置关掉它,并滚动重启所有TiKV实例,可以发现I/O Util回落到了相对正常的水平
解决
关闭sync_log非常简单直接,但却是以牺牲数据可靠性作为trade-off的(当然对于云环境而言影响不算大)。如果不想在TiDB层面做改动,则需要调整磁盘挂载参数来变相降低JBD2的负载。例如:
在挂载参数中添加data=writeback启用ext4的写回日志模式(默认为ordered),即只产生元数据日志,不产生数据日志,并且不保证数据与元数据落盘的顺序;
在挂载参数中添加commit=60来降低ext4主动提交事务的频率,单位为秒,默认为5秒。
另外,可以用fio等工具对空盘(注意一定要是空盘)做个fsync IOPs的测试,如果此值过低,应考虑更换性能更高的盘。
原文:https://www.cnblogs.com/bliane/p/14601712.html
如果您也喜欢它,动动您的小指点个赞吧
 602392714
602392714
 清零编程群
清零编程群