mysql操作语言
1.数据定义语言DDL(Data Definition Language)
对象: 数据库和表
关键词: create alter drop truncate(删除当前表再新建一个一模一样的表结构)
创建数据库:create database school;
删除数据库:drop database school;
切换数据库:use school;
创建表:create table student(
id int(4) primary key auto_increment,
name varchar(20),
score int(3)
);
查看数据库里存在的表:show tables;
注意:
varchar类型的长度是可变的,创建表时指定了最大长度,定义时,其最大值可以取0-65535之间的任意值,但记录在这个范围内,使用多少分配多少,
varchar类型实际占用空间为字符串的实际长度加1。这样,可有效节约系统空间。varchar是mysql的特有的数据类型。
char类型的长度是固定的,在创建表时就指定了,其长度可以是0-255之间的任意值。虽然char占用的空间比较大,但它的处理速度快。
修改表:alter table student rename (to) teacher;
alter table student add password varchar(20);
alter table student change password pwd varchar(20);
alter table student modify pwd int;
alter table student drop pwd;
删除表:drop table student;
查看生成表的sql语句:show create table student;
查看表结构:desc student;
2.数据操纵语言DML(Data Manipulation Language)
对象:纪录(行)
关键词:insert update delete
插入:insert into student values(01,‘tonbby‘,99); (插入所有的字段)
insert into student(id,name) values(01,‘tonbby‘); (插入指定的字段)
更新:update student set name = ‘tonbby‘,score = ‘99‘ where id = 01;
删除:delete from tonbby where id = 01;
注意:
开发中很少使用delete,删除有物理删除和逻辑删除,其中逻辑删除可以通过给表添加一个字段(isDel),若值为1,代表删除;若值为0,代表没有删除。
此时,对数据的删除操作就变成了update操作了。
truncate和delete的区别:
truncate是删除表,再重新创建这个表。属于DDL,delete是一条一条删除表中的数据,属于DML。
3.数据查询语言DQL(Data Query Language)
select ... from student where 条件 group by 分组字段 having 条件 order by 排序字段
执行顺序:from->where->group by->having->order by->select
注意:group by 通常和聚合函数(avg(),count()...)一起使用 ,经常先使用group by关键字进行分组,然后再进行集合运算。
group by与having 一起使用,可以限制输出的结果,只有满足条件表达式的结果才会显示。
having和where的区别:
两者起作用的地方不一样,where作用于表或视图,是表和视图的查询条件。having作用于分组后的记录,用于选择满足条件的组。
4.数据控制语言DCL(Data Control Language)
1.MySQL之DCL设置root指定的ip访问
进入mysql:mysql -uroot -p或者mysql -uroot -h127.0.0.1 -p(host默认为127.0.0.1)
mysql> use mysql;
mysql> update user set host = ‘ip‘ where user = ‘root‘;
mysql> select host, user from user;
mysql> flush privileges;
2.MySQL之DCL修改密码以及忘记密码的解决
MySQL8.0修改密码问题:
MySQL8.0后请使用alter修改用户密码,因为在MySQL8.0以后的加密方式为caching_sha2_password,如果使用update修改密码会给user表中root用户的authentication_string字段下设置newpassowrd值,当再使用alter user ‘root‘@‘localhost‘ identified by ‘newpassword‘修改密码时会一直报错,必须清空后再修改,因为authentication_string字段下只能是MySQL加密后的43位字符串密码,其他的会报格式错误,所以在MySQL8.0以后能修改密码的方法只能是:ALTER USER ‘root‘@‘localhost‘ IDENTIFIED WITH mysql_native_password BY ‘你的密码‘;
MySQL8.0.12重置root密码
使用登录时跳过验证的方式重置root密码 步骤1:先关闭MySQL服务,然后使用“–skip-grant-tables”配置项,跳过权限验证方式重启MySQL服务:
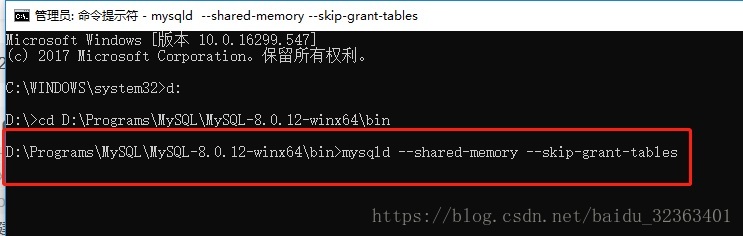
这里使用的指令是“mysqld –shared-memory –skip-grant-tables”,若是只是“mysqld –skip-grant-tables”的话,会导致mysqld启动失败,提示“TCP/IP, –shared-memory, or –named-pipe should be configured on NT OS”错误。经过测试,只有加上“–shared-memory”才能启动、访问数据库。 步骤2:在打开一个终端,在里面使用免密的方式登陆数据库,直接运行mysql即可:
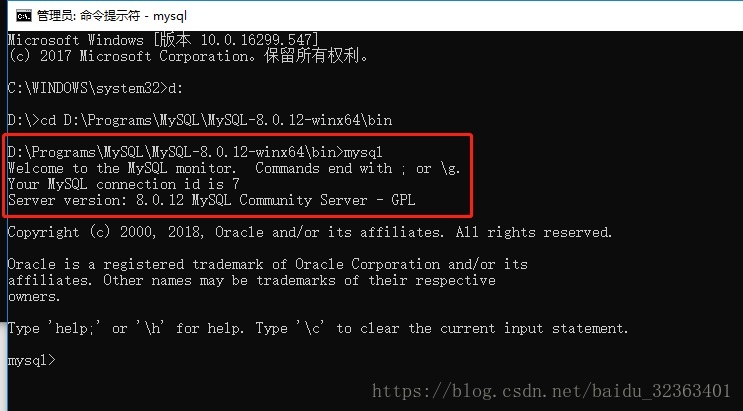
步骤3:首先刷新执行指令“FLUSH PRIVILEGES;”,刷新权限:
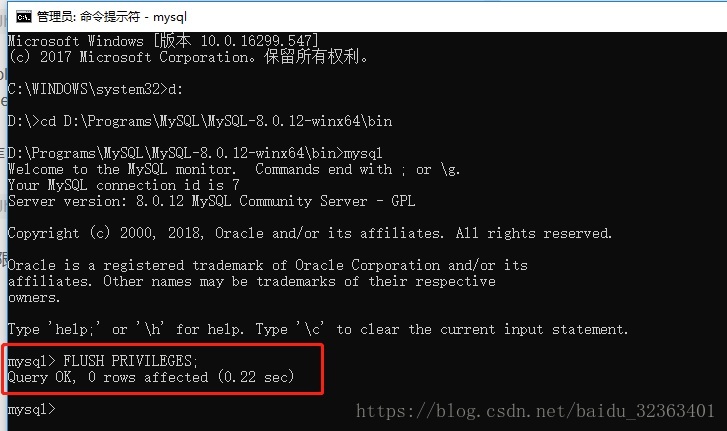
然后执行指令“ALTER USER ‘root’@’localhost’ IDENTIFIED BY ‘new_psd_123’;”进行密码更新操作,“new_psd_123”即是设置的新密码:
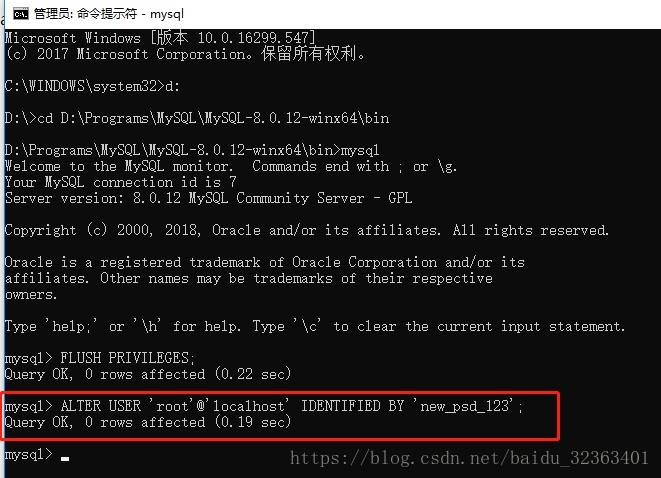
设置完成后,正常启动MySQL服务,使用用户名密码进行验证是否设置成功!
3.MySQL之DCL普通用户的创建授权以及权限回收
一般地,一个项目对应一个数据库;
(1)创建用户
create user 用户名@‘IP地址‘ identified by ‘密码‘;
注意:此用户只能在制定的IP上使用 所有的IP要用%。
(2)用户授权
grant 权限1,权限2,...... on 数据库名.* to 用户名 @IP地址或者%
注意:所有的数据库就用.,所有的权限就用all或者all privileges
(3)撤销权限
revoke 权限1,权限2,...... on 数据库名.*from 用户名 @IP地址或者%
4.MySQL之DCL用户权限的查看以及用户的删除
(1)查看权限
show grants for 用户名@IP地址;
(2)删除用户
drop user 用户名@IP地址;
mysql数据类型
整数 :4个
bit (1-64)
tinyint (-128~127)
smallint(-32768~32767)
int(-2147483648~2147483647)
小数:3个
float
double
decimal
时间日期: 4个
data(日期存储范围为:1000-01-01~9999-12-31)
datetime(日期和时间的组合:1000-01-01 00:00:00~9999-12-31 23:23:23)
timestamp(时间戳,转换成本地时间再存)
time(范围-838:59:59~838:59:59)
字符串:
char(M) M固定长度,范围(0~255)(长度不够后面空代替)
varchar(M) M变长 (多长就是多长,效率比char低)
text 长文本
mysql中没有boolean,我们可以使用tinyint标识:0 false 1 true
表结构操作
0.杂项
(1)show tables; (展示所有存在的表)
(2)desc user;(刷新展示当前表)
(3)show create table user; (展示表)
1.创建表
create table test2(
id int(10),
name varchar(255)
);
2.插入数据
insert into test2 value(10,"zhangsan"); //单个
insert into test2 values(10,"zhangsan"),(10,"zhangsan");//多个
3.修改列类型
alter table user modify userage varchar(5);
4.增加列
alter table user add userpwd varchar(20);
5.删除列
alter table user drop userage;
6.列改名
alter table user change userpwd password varchar(20);
7.更改表名
alter table user rename users;
rename table users to user;
8.删除表
drop table test1;
9.删除表中全部数据 (删除表中数据-表结构不删除)
truncate table test1;
10.删除表中数据(一条一条删-效率低)
delete from user;
用delete删除 数据,然后添加。可以看到添加之后id标识不连续。(说明delete删除不释放空间)
truncate 与delete 比较:
truncate table 在功能上与不带 WHERE 子句的 delete语句相同:二者均删除表中的全部行。
truncate 比 delete速度快,且使用的系统和事务日志资源少。
truncate 操作后的表比Delete操作后的表要快得多。
当表被清空后表和表的索引讲重新设置成初始大小,而delete则不能。
约束
约束的含义都很重要 操作时只有建表时构建约束最重要
1.非空约束
建表时加: create table pers(name varchar(20) not null ,age int(5));
删除:alter table pers modify name varchar(20);
建表后加:alter table pers modify name varchar(20) not null;
2.唯一约束
建表时加:create table pers1(name varchar(20) unique ,age int(5));
删除: alter table pers1 drop index name;
建表后加: alter table pers1 add constraint unique(name);
给多列增加唯一约束: alter table pers1 add constraint unique(name,age);
3.主键(用来唯一标识当前行数据的列)约束 唯一,非空,一张表只有一个主键
建表时加:create table pers2 (name varchar(20) primary key,age int(5));
删除: alter table pers2 drop primary key;
建表后加:alter table pers2 add constraint primary key(name);
联合主键:create table pers3 (name varchar(20),age int(5),primary key(name,age));
两列都不许为null 两列不允许同时重复
4.自动增长:一般给数字列加,并且只能给主键列加
建表时加:create table 举个栗子 (id int(5) primary key auto_increment,name varchar(20));
删除:alter table 举个栗子 modify id int(5);
建表后加: alter table 举个栗子 modify id int(5) auto_increment;
5.区分大小写(注意window系统不区分大小写,liunx系统区分大小写)
create table users1 (name varchar(5) binary primary key,age int(3));
删除: alter table users1 modify name varchar(5)
增删改操作
1.插入数据
insert into user(username,password) values("xx2","654321");
insert into user values("xx1","123456");
insert into user(username) values("xx3");
2.删除全部数据
delete from user;(查询方式删除)
truncate table user;(直接删除)
drop table user ;(连表一起删除)
删除指定行数据:
delete from users1 where name=‘XX1‘;
3.修改数据
update 举个栗子 set name="qqq";
update 举个栗子 set name="xx2" where id=2;
4.给定列初始值
create table stus (
name varchar(20) default ‘zhangjun‘,
age int(3) default 20,
qq1 varchar(20),
qq2 int(3)
);
查询
1.查看若干列
select name,pwd from users;
2.取别名
select name ‘姓名‘,pwd from users;
3.合并列显示
select concat(name,pwd) ‘姓名+密码‘ from users;
select concat(name,"++",pwd) ‘姓名+密码‘ from users;
4.只查看若干行
select * from users where age>=23;
select * from users where age<>23;
select * from users where name >‘lishuo1‘;
5.可以结合算术表达式使用
select age*10 from users;(查出来每一个乘以10);
6.查找并去重
select distinct * from users;
select distinct name from users;
7.查找指定区间的数据
select * from users2 where salary>=500 AND salary<=3000;
select * from users2 where salary between 500 and 3000;
select * from users2 where salary in (1000,1500);
8.查null值
select * from users2 where salary is null;
9.模糊查询
查询名字中带a的人
select * from users2 where name like ‘%a%‘;
查询名字以a开头的人
select * from users2 where name like ‘a%‘;
查询名字长度为2并且以a结尾的人
select * from users2 where name like binary ‘%_a‘;
10.与或非
select * from worker where sex=‘man‘ and salary >1000;
select * from worker where salary >1000 and sex =‘man‘ or sex=‘woman‘ and dept=‘技术部‘;
select * from worker where dept is not null;
select * from worker where salary not between 1000 and 5000;
select * from worker where salary not in(1000,6000);
11.对查询结果排序
select * from worker where salary between 1000 and 5000 order by salary;
select * from worker where salary between 1000 and 5000 order by salary desc
(倒序,从大到小排序)
select name ‘姓名‘,salary ,salary/10 ‘税金‘ from worker where salary>3000 order by salary;
12.加密

13.查询日期时间
select curdate(),curtime(),now() from dual;
+------------+-----------+---------------------+
| curdate() | curtime() | now() |
+------------+-----------+---------------------+
| 2015-08-14 | 14:56:59 | 2015-08-14 14:56:59 |
+------------+-----------+---------------------+
select year(now()),hour(now()),minute(now()),monthname(now()) from dual;
聚合函数,求总和,均值,最大,最小
select count(salary) from worker; //计数的聚合函数
select count(*) from worker; //计数的聚合函数
select avg(salary) from worker; avg值
select sum(salary),max(salary),min(salary) from worker;
分组
select dept, sum(salary) from worker group by dept;
出现在SELECT列表中的字段,要么出现在组合函数里,要么出现在GROUP BY 子句中
分组后限定
分组前限定用where,分组后限定用having
select dept, sum(salary) from worker group by dept having sum(salary)>=3000
select dept, sum(salary) from worker where sex=‘man‘ group by dept ;
select dept, sum(salary) from worker where sex=‘man‘ group by dept having sum(salary)>=1000 ;
limit限定
只看前5行数据
select * from worker limit 5;
6-8行数据
select * from worker limit 5,3;
select 查询完整语法
select查询完整语法格式如下:
selet[select 选项]
字段列表[字段别名] /*
from 数据源
[where条件字句]
[group by 字句]
[having 字句]
[order by 字句]
[limit 字句]
【1】select选项
即select对查出来的结果的处理方式
① all :默认的,保留所有的结果; ② distinct:去重,将查出来的结果重复的去掉(所有字段值都相同才叫重复)。
下面两条语句等价:
select * from p_user_2;
SELECT all * from p_user_2
select DISTINCT NAME,age from p_user_2 
【2】字段别名
多表操作时可能会有字段名字重复,此时可重命名。
示例如下:
select NAME [as] ‘用户名‘,age [as] ‘年龄‘ from p_user_2; -- as可缺省
【3】数据源
数据源:数据的来源,关系型数据库数据来源为数据表。本质上只要保证数据类似二维表,最终都可以作为数据源。
数据源分多种:
单表数据源,多表数据源(多表查询)以及查询语句(from子句)。
单表数据源 :
select * from p_user
多表数据源:
select * from p_user,c_user 可以自定义列,别名进行查询。如果默认查询且两表存在重复字段名,后置+1(此处用的Navicat for MySQL,如果在dos下,字段不会+1):

需要注意的是:这样查询效果是从一张表中取出一条记录,去另外一张表中匹配所有的记录,而且全部保留(包括记录数和字段数) 。将这种结果称之为–笛卡尔积(交叉连接)。
查询语句:
select * from (select NAME,age from p_user) as t;
?
-- from后面查询语句结果作为一个临时表;
-- 表一定要有别名
【4】where子句
where是唯一一个直接从磁盘获取数据的时候就开始判断的条件。 从磁盘取出一条记录,开始where判断。判断如果成立,则保存到内存中;失败则直接放弃。
where子句:用来判断数据筛选数据。返回结果0或者1,0–false;1–true。
判断条件:
比较运算符:<,>,>=,<=,!=,<>,=,like,between and,in/not in ;
逻辑运算符:and(&&),or(||),not(!)。 in 是一个区间,一个集合,准备的说是一个散列值的序列。
between是两个数直接的区间范围,左边的数必须小于或者等于右边的数字。
select * from p_user where age BETWEEN 10 and 20;
select * from p_user where age <20 and age >10;
select * from p_user where age in(10,11,12,15,19,18)
【5】group by 子句
group by:按照某个条件进行分组,记录相同的(按照数据表中保存的次序)只保留一条,然后根据条件字段进行排序默认升序。
即,对分组的结果合并之后的整个结果进行排序!
分组的意义:是为了统计数据(按组统计:按分组字段进行统计,一个组只统计一条数据)。
MySQL 提供的统计函数:
count():统计分组后的记录数,即每一组有多少记录;
max():统计每组中的最大值;
min():统计每组中的最小值;
avg():统计每组中的平均值;
sum:对每组进行求和。 语法格式如下:
select [columns] from table_name [where..] group by [columns] [having ...] 需要说明的是,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中!!!
详细参考group by实例分析
下面操作是在Navicat for MySQL中进行,该工具对语法进行了处理。
① 按照年龄进行分组:
select * from p_user GROUP BY age; 
注意,group by 默认进行了排序,其age列效果同下 :
select DISTINCT age from p_user ORDER BY age asc; 
② 按照年龄分组并count :
select *, COUNT(*) from p_user GROUP BY age; 
count( ):里面可以使用两种参数:*代表统计记录,字段名代表统计对应的字段(NULL不统计)。
count()是分组之后统计每组的记录数,单独执行count查询只会返回一行结果!!!
③ 按照年龄分组在count基础上取最大、最小值:
select *,count(age), max(id),min(id) from p_user GROUP BY age; 
④ 多字段分组:
分组之后整合的结果也是先按照sex后按照age排序。
select sex,age,COUNT(age) from p_user GROUP BY sex,age; 
如果想统计每组中的name呢?可以使用GROUP_CONCAT()函数。
group_concat() : 可以对分组的结果中的某个字段进行字符串链接(保留该组所有的某个字段)。
select sex,age,COUNT(age),GROUP_CONCAT(name) from p_user GROUP BY sex,age 
回溯统计:with rollup 。
解释如下:任何一个分组后都会有一个小组,最后都需要根据当前分组的字段向上级分组进行汇报统计。
回溯统计的时候会将分组字段置空。
正常分组如下:
SELECT sex,COUNT(*) from p_user GROUP BY sex;

回溯统计如下:
select sex,count(*)from p_user GROUP BY sex with rollup;

多字段回溯统计
正常统计1-九条记录:
select sex,age,COUNT(age),GROUP_CONCAT(name) from p_user GROUP BY age,sex

回溯统计1-16条:**
select sex,age,COUNT(age),GROUP_CONCAT(name) from p_user GROUP BY age,sex WITH ROLLUP

按照年龄进行分组,之后又针对每个年龄进行sex分组。那么首先向sex的上级分组age进行汇报统计,然后age再向顶级分组进行汇报统计。age有六组,故进行六次(sex-age)汇报统计,最后(age - 顶级)进行一次总的汇报统计。
正常统计2-九条记录:
select sex,age,COUNT(age),GROUP_CONCAT(name) from p_user GROUP BY sex,age

回溯统计2-12条:**
select sex,age,COUNT(age),GROUP_CONCAT(name) from p_user GROUP BY sex,age WITH ROLLUP

首先根据sex进行分组,之后再根据age进行分组。那么汇报统计首先是age-sex,因为sex只有两组,故回溯统计两次。最后sex-顶层,进行一次回溯统计。共三次,故12条
多字段回溯:考虑第一层分组会有此回溯;第二次分组要看第一次分组的组数,组数是多少,回溯就是多少,然后加上第一层回溯即可。
【6】having子句
Having子句:与where子句一样进行条件判断的。
where是针对磁盘数据进行判断,进入到内存之后会进行分组操作,而分组结果需要having进行过滤。
having能做where能做的几乎所有事情,反之不能。
① 分组统计的结果或者统计函数只有having能使用,where不可以。
select age,count(*) from p_user group by age having count(*)>1; -- where 不可以,因为where是在group by前进行过滤,而count(*)是在group by之后统计。
② having能够使用字段别名,where不能。where是从磁盘获取数据,名字只可能是字段名,别名是在字段进入内存后才会产生。
select age,count(*) as total from p_user group by age having total>1; select name as 名字,age from p_user having 名字 like ‘%明%‘;
-- 如果换成where则错误。
【7】order by子句
order by : 排序,根据某个字段进行升序或者降序排序,依赖校对集。
语法:order by 字段名 [asc|desc]默认asc-升序,desc是降序。
排序可以进行多字段排序:先根据某个字段进行排序,然后排序好的内部,再按照某个数据进行再次排序。
select * from p_user ORDER BY sex,age;
【8】limit子句
limit子句是一种限制结果的子句:限制数量。
① 限制查询长度(记录数)
select * from p_user limit 2;
② 限制起始位置和偏移长度,limit m,n
常用来进行数据分页; 记录数从 0 开始;
select * from p_user limit 2 ,10;
-- 查询从第二条到第十条的数据 数据分页:
分页可以为用户节省时间,提高服务器响应效率,减少资源的浪费。 对于服务器来讲,每次根据用户选择的页码来获取不同的数据,limit offset,length。
length:每页显示的数据量,基本不变。 offset:(页码-1)*length(因为记录数从0开始哦)。
SQL语句执行顺序
【1】SQL执行语法顺序
--查询组合字段
(5)select (5-2) distinct(5-3) top(<top_specification>)(5-1)<select_list>
--连表
(1)from (1-J)<left_table><join_type> join <right_table> on <on_predicate>
(1-A)<left_table><apply_type> apply <right_table_expression> as <alias>
(1-P)<left_table> pivot (<pivot_specification>) as <alias>
(1-U)<left_table> unpivot (<unpivot_specification>) as <alias>
--查询条件
(2)where <where_pridicate>
--分组
(3)group by <group_by_specification>
--分组条件
(4)having<having_predicate>
--排序
(6)order by<order_by_list>
(7)limit <n,m>//MySQL支持limit Oracle sqlserver支持top
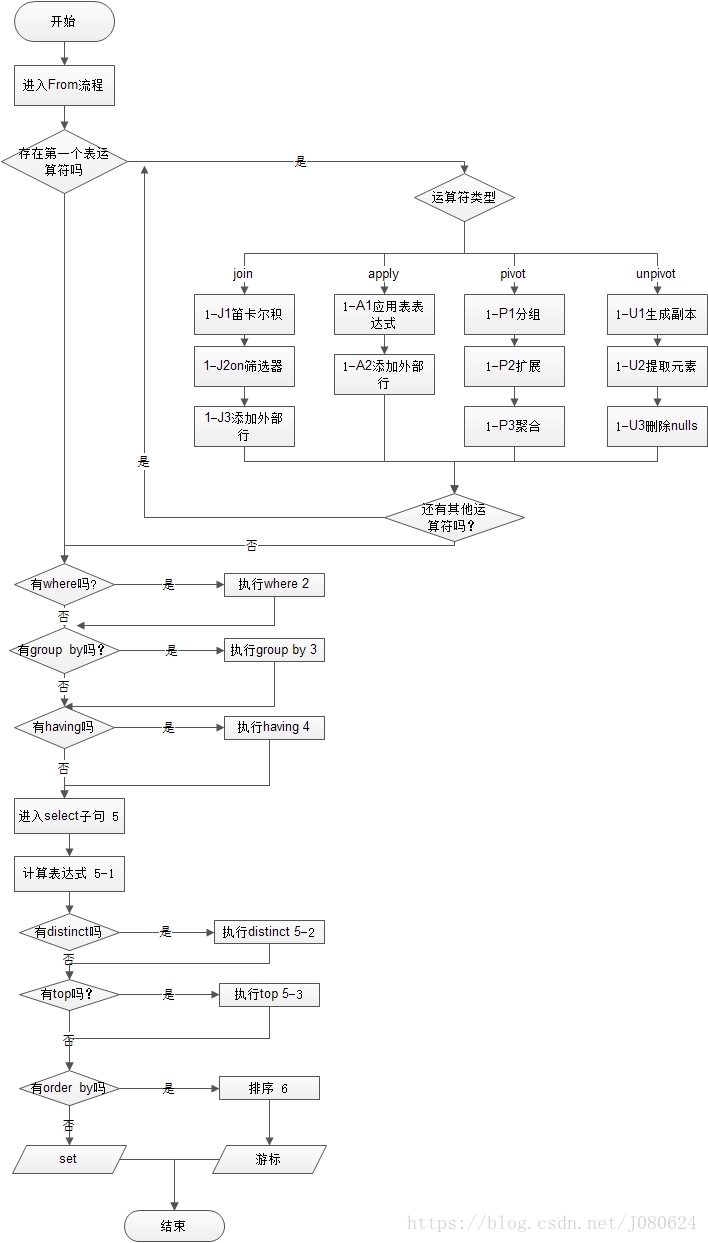
说明: 1、顺序为有1-7,7个大步骤,然后细分,5-1,5-2,5-3,由小变大顺序,1-J,1-A,1-P,1-U,为并行次序。
2、执行过程中也会相应的产生多个虚拟表,以配合最终的正确查询。
流程图如下:
【2】实例分析
① 创建两个表如下:

② 创建两个表并插入数据
USE [test]
GO
/****** Object: Table [dbo].[Member] Script Date: 2014/12/22 14:05:17 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Member](
[id] [int] IDENTITY(1,1) NOT NULL,
[Name] [nvarchar](30) NULL,
[phone] [varchar](15) NULL,
CONSTRAINT [PK_MEMBER] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
/****** Object: Table [dbo].[Order] Script Date: 2014/12/22 14:05:17 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Order](
[id] [int] IDENTITY(1,1) NOT NULL,
[member_id] [int] NULL,
[status] [int] NULL,
[createTime] [datetime] NULL,
CONSTRAINT [PK_ORDER] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
SET IDENTITY_INSERT [dbo].[Member] ON
GO
INSERT [dbo].[Member] ([id], [Name], [phone]) VALUES (1, N‘张龙豪‘, N‘18501733702‘)
GO
INSERT [dbo].[Member] ([id], [Name], [phone]) VALUES (2, N‘Jim‘, N‘15039512688‘)
GO
INSERT [dbo].[Member] ([id], [Name], [phone]) VALUES (3, N‘Tom‘, N‘15139512854‘)
GO
INSERT [dbo].[Member] ([id], [Name], [phone]) VALUES (4, N‘Lulu‘, N‘15687425583‘)
GO
INSERT [dbo].[Member] ([id], [Name], [phone]) VALUES (5, N‘Jick‘, N‘13528567445‘)
GO
SET IDENTITY_INSERT [dbo].[Member] OFF
GO
SET IDENTITY_INSERT [dbo].[Order] ON
GO
INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (1, 1, 3, CAST(0x0000A40900B3BBFB AS DateTime))
GO
INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (2, 2, 1, CAST(0x0000A40900B3CEF2 AS DateTime))
GO
INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (3, 3, 4, CAST(0x0000A40900B3D2D0 AS DateTime))
GO
INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (4, 4, 0, CAST(0x0000A40900B3D660 AS DateTime))
GO
INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (5, 5, 1, CAST(0x0000A40900B3D9B9 AS DateTime))
GO
INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (6, 6, 2, CAST(0x0000A40900B3DFEA AS DateTime))
GO
INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (7, NULL, 0, CAST(0x0000A40900E34971 AS DateTime))
GO
SET IDENTITY_INSERT [dbo].[Order] OFF
GO
ALTER TABLE [dbo].[Order] ADD DEFAULT (getdate()) FOR [createTime]
GO
EXEC sys.sp_addextendedproperty @name=N‘MS_Description‘, @value=N‘编号‘ , @level0type=N‘SCHEMA‘,@level0name=N‘dbo‘, @level1type=N‘TABLE‘,@level1name=N‘Member‘, @level2type=N‘COLUMN‘,@level2name=N‘id‘
GO
EXEC sys.sp_addextendedproperty @name=N‘MS_Description‘, @value=N‘姓名‘ , @level0type=N‘SCHEMA‘,@level0name=N‘dbo‘, @level1type=N‘TABLE‘,@level1name=N‘Member‘, @level2type=N‘COLUMN‘,@level2name=N‘Name‘
GO
EXEC sys.sp_addextendedproperty @name=N‘MS_Description‘, @value=N‘电话‘ , @level0type=N‘SCHEMA‘,@level0name=N‘dbo‘, @level1type=N‘TABLE‘,@level1name=N‘Member‘, @level2type=N‘COLUMN‘,@level2name=N‘phone‘
GO
EXEC sys.sp_addextendedproperty @name=N‘MS_Description‘, @value=N‘会员表‘ , @level0type=N‘SCHEMA‘,@level0name=N‘dbo‘, @level1type=N‘TABLE‘,@level1name=N‘Member‘
GO
EXEC sys.sp_addextendedproperty @name=N‘MS_Description‘, @value=N‘编号‘ , @level0type=N‘SCHEMA‘,@level0name=N‘dbo‘, @level1type=N‘TABLE‘,@level1name=N‘Order‘, @level2type=N‘COLUMN‘,@level2name=N‘id‘
GO
EXEC sys.sp_addextendedproperty @name=N‘MS_Description‘, @value=N‘会员编号‘ , @level0type=N‘SCHEMA‘,@level0name=N‘dbo‘, @level1type=N‘TABLE‘,@level1name=N‘Order‘, @level2type=N‘COLUMN‘,@level2name=N‘member_id‘
GO
EXEC sys.sp_addextendedproperty @name=N‘MS_Description‘, @value=N‘订单状态‘ , @level0type=N‘SCHEMA‘,@level0name=N‘dbo‘, @level1type=N‘TABLE‘,@level1name=N‘Order‘, @level2type=N‘COLUMN‘,@level2name=N‘status‘
GO
EXEC sys.sp_addextendedproperty @name=N‘MS_Description‘, @value=N‘下单日期‘ , @level0type=N‘SCHEMA‘,@level0name=N‘dbo‘, @level1type=N‘TABLE‘,@level1name=N‘Order‘, @level2type=N‘COLUMN‘,@level2name=N‘createTime‘
GO
EXEC sys.sp_addextendedproperty @name=N‘MS_Description‘, @value=N‘订单表‘ , @level0type=N‘SCHEMA‘,@level0name=N‘dbo‘, @level1type=N‘TABLE‘,@level1name=N‘Order‘
GO
③ 编写查询语句
select top(4) status , max(m.id) as maxMemberID from [dbo].[Member] as m right outer join [dbo].[Order] as o on m.id=o.member_id where m.id>0 group by status having status>=0 order by maxMemberID asc
④ 实例语句分步骤分析
第一阶段:from开始
1.1 加载左表
from [dbo].[Member] as m
查询结果:member表中的所有数据。
查询结果:member表中的所有数据。
1.2 这里应该是 right outer join ,但是这里在sql中被定义分解为2个步骤,即join ,right outer join 。表达式关键字从左到右,依次执行。
join [dbo].[Order] as o 查询结果:存入虚拟表vt1,为两个表的笛卡尔集合。
1.3、on 筛选器
on m.id=o.member_id
查询结果如下:
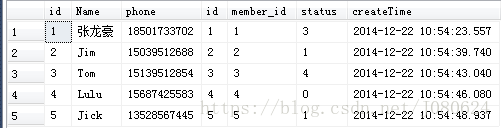
从上一步的笛卡尔集中的35条数据中删除掉不匹配的行,得到5条数据,存入虚拟表Vt2。
1.4 、添加外部行(outer row)
right outer join [dbo].[Order] as o
查询结果如下:
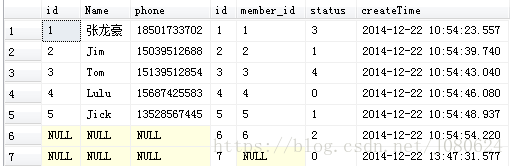
右表(order)作为保留表,把剩余的数据重新添加到上一步的虚拟表vt2中,生成虚拟表vt3。
第二阶段:where 阶段
where m.id>0
查询结果:存入虚拟表vt4,为筛选的条件为true的结果集,这里加入一个记忆点,就是,where的筛选删除为永久的,而on的筛选删除为暂时的,因为on筛选过后,有可能会经过outer添加外部行,重新把数据加载回来,而where则不能。
第三阶段:group by分组
group by status
查询结果:存入vt5,以status列的数值开始分组,即status列,值一样的分为一组,这里的两个null在三值逻辑中被视为true。三值逻辑:true,false,null。此三值,null为未知,是数据的逻辑特色,有的地方两个null相等为ture,在有些地方则为false。
第四阶段:having 筛选
having status>=0
查询结果:筛选分好组的组数据,把不满足条件的删除掉。
查询结果:筛选分好组的组数据,把不满足条件的删除掉。
第五阶段:select 查询挑拣计算列
5.1、计算表达式
select status , max(m.id)
查询结果:从分过组的数据中计算各个组中的最大m.id,列出要筛选显示的列。
5.2、distinct过滤重复
5.3、top 结合order by 筛选 多少行,但这里的数据没有排序只是把多少行数据列出来而已。
第六阶段:order by
排序显示
【3】MySQL语法实例
MySQL完整语法与执行顺序如下:
(7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP BY <group_by_list> (6) HAVING <having_condition> (9) ORDER BY <order_by_condition> (10) LIMIT <limit_number>
多表查询(内连接,外连接,子查询)
用两个表(a_table、b_table),关联字段a_table.a_id和b_table.b_id来演示一下MySQL的内连接、外连接( 左(外)连接、右(外)连接、全(外)连接)。
MySQL版本:Server version: 5.6.31 MySQL Community Server (GPL)
数据库表:a_table、b_table
主题:内连接、左连接(左外连接)、右连接(右外连接)、全连接(全外连接)

内连接:
\1. 交叉连接查询(基本不会使用-得到的是两个表的乘积) (这种查询时候会产生笛卡尔积) 语法: select * from A,B; \2. 内连接查询(使用的关键字 inner join -- inner可以省略) 隐式内连接: select * from A,B where 条件; 显示内连接: select * from A inner join B on 条件;
执行语句为:select * from a_table a inner join b_table bon a.a_id = b.b_id;

总结:当且仅当两个表中的数据都符合on后面的条件的时候,才会被select出来.

外连接
左外连接:**
外连接查询(使用的关键字 outer join -- outer可以省略) 左外连接:left outer join
语句:select * from a_table a left join b_table bon a.a_id = b.b_id;
执行结果:

总结:在查询的时候,以left join 这个关键字左边的表为主表,会将这个表中的数据全部查询出来,如果右表中没有这条数据,则用NULL字段表示.

右外连接:
右外连接:right outer join select * from A right outer join B on 条件;
语句:select * from a_table a right outer join b_table b on a.a_id = b.b_id;
执行结果:

总结:在查询的时候,会以right join 这个关键字右边的表为主,然后将符合条件的查询出来,左表中没有的字段,使用NULL进行补充

子查询
一条select语句结果作为另一条select语法一部分(查询条件,查询结果,表等)。
语法: select ....查询字段 ... from ... 表.. where ... 查询条件
#3 子查询, 查询“化妆品”分类上架商品详情 #隐式内连接 SELECT p.* FROM products p , category c WHERE p.category_id=c.cid AND c.cname = ‘化妆品‘; #子查询 ##作为查询条件 SELECT * FROM products p WHERE p.category_id = ( SELECT c.cid FROM category c WHERE c.cname=‘化妆品‘ ); ##作为另一张表 SELECT * FROM products p , (SELECT * FROM category WHERE cname=‘化妆品‘) c WHERE p.category_id = c.cid;
查询结果:
总结:可以将一条查询语句作为另外一个查询语句的条件和表,再次进行查询.
索引和视图
二叉树索引,哈希索引
1.创建
create view myv1 as select empname from emp e1 where salary =(select max(salary) from emp e2 where e2.deptid=e1.deptid);
create view v1 as SELECT * FROM table1 WHERE id=2 AND name="李四";
2.查看
show tables;
3.删除
drop view myv1;
4.修改
alter view myv1 as select empname,salary,sex from emp;
5.视图和原表的关系
原表中数据发生变化,则视图数据变化,反之亦然
注意向视图中插入数据的操作并不总是能执行
6.查看索引
哈希索引 BTree索引
show index from emp;
7.添加索引:如果有某一列经常作为查询的依据,那么我们可以给该列加上一个索引
create index in1 on emp (salary);
create index ind1 on user (name);
主键列默认会有索引 唯一约束列默认会有索引
8.删除索引
alter table emp drop index empname;
drop index in1 on emp;
只有Where后面的第一个约束的索引是生效的,其他的是不生效的
select * from user where username=‘dahuang‘ and userpwd=‘123456‘
总结:
创建索引和删除索引:
create index ind1 on user(name);
drop index ind1 on user;
创建视图和删除视图:
create view v1 as SELECT * FROM user WHERE id=2 AND name="李四";
drop VIEW v1;
触发器
语法
CREATE TRIGGER 触发器名字
AFTER
UPDATE ON 表名
FOR EACH ROW
BEGIN
IF (...) and (...) THEN #这里有一点要特别注意,条件判断相等是应该写 = ,而不是 ==
IF (...) or (...) THEN
要执行的sql
ELSE
要执行的sql
END IF;
ELSE
IF (...) or (...) THEN
要执行的sql
END IF;
END IF;
END
一个实例
CREATE TRIGGER `sync_col1_to_table2` AFTER UPDATE ON `table1` FOR EACH ROW BEGIN IF NEW.col1 != OLD.col1 THEN UPDATE `table2` SET `col1` = NEW.`col1` WHERE XXX; END IF; END
外键
外键约束: foreign key
B表要出现A表中的数据,那么B表中的数据就不能超出A表中的数据范畴
B表中的引用数据的这一列,我们就加一个外键约束即可,此列取值,全都在A表的主键中
外键:就是另一张表的主键数据
外键列数据可以重复,也可以是null,就一个要求,不超出数据来源表的数据范畴即可
重点掌握!!
存储过程和函数
文章内容来源于网络。
原文:https://www.cnblogs.com/isoma/p/12568600.html
如果您也喜欢它,动动您的小指点个赞吧
 602392714
602392714
 清零编程群
清零编程群